

Wenn KI auf IoT-Sicherheit trifft: Warum LLMs statische Analyse-Tools noch nicht ersetzen können

KI-Modelle wie GPT-4o oder Gemini 2.5 Pro sind beeindruckend vielseitig – aber können sie in sicherheitskritischen IoT-Umgebungen das ersetzen, was formale Analysetools seit Jahren leisten? Eine neue Peer-Review-Studie liefert eine differenzierte Antwort: beide Ansätze allein reichen nicht, zusammen schon.
- Forscher der Toronto Metropolitan University haben GPT-4o, Gemini 2.5 Pro, DeepSeek-R1 und zwei Llama-Varianten gegen ein symbolisches Analyse-Tool beim Erkennen von Regelinteraktionsbedrohungen in openHAB-Automatisierungssystemen getestet – an 145 realen und 2.495 synthetisch mutierten Regelsätzen.
- LLMs sind strukturell blind bei regelübergreifenden Abhängigkeiten und halluzinieren unter Stress; statische Analyse-Tools finden zuverlässig alle Bedrohungen, erzeugen aber so viele Fehlalarme, dass sie in der Praxis schwer nutzbar sind.
- Der von den Forschern entwickelte Hybrid-Ansatz kombiniert beide Verfahren und steigert die Erkennungspräzision von 73% auf 93% – ein Ergebnis, das zeigt, wie neuronale und symbolische KI sich gegenseitig ergänzen statt ersetzen.
Das Sicherheitsproblem in vernetzten Hausautomationssystemen
Wer ein Smart Home betreibt, legt typischerweise Automatisierungsregeln fest: Wenn die Haustür nach 23 Uhr geöffnet wird, soll die Alarmanlage aktivieren. Wenn es 8:30 Uhr morgens ist und ein Werktag, sollen Küchenlicht, Kaffeemaschine und Morgenradio angehen. Solche Regeln sind einzeln betrachtet harmlos – in Kombination können sie jedoch unbeabsichtigte und im schlimmsten Fall gefährliche Wechselwirkungen erzeugen.
Ein konkretes Beispiel aus der Studie: Regel 1 schaltet morgens um 8:30 Uhr automatisch das Flurlich ein – und Regel 2 öffnet Haustür und Garagentor, sobald das Flurlicht brennt, weil sie davon ausgeht, dass jemand das Haus verlässt. Ist der Bewohner aber gar nicht zu Hause oder beschließt er, heute im Homeoffice zu bleiben, öffnet das System trotzdem unbemerkt Haustür und Garage – für Stunden. Eine einzelne Regel, die eine weitere auslöst: das nennen die Forscher eine Trigger Cascade.
In der Forschung werden solche Konstellationen als Rule Interaction Threats (RITs) bezeichnet – Regelinteraktionsbedrohungen, die aus dem Zusammenspiel mehrerer Automatisierungsregeln entstehen. Sie lassen sich grob in drei Kategorien einteilen: Action Contradictions (zwei Regeln geben einem Gerät widersprüchliche Befehle), Trigger Cascades (eine Regel löst unbeabsichtigt eine Kette weiterer Regeln aus) und Condition Cascades (sich gegenseitig beeinflussende Bedingungen erzeugen unvorhersehbare Zustände).
Plattformen wie openHAB, eine der verbreitetsten Open-Source-Heimautomationslösungen, setzen auf sogenannte TAC-Regeln (Trigger–Action–Condition), also das Schema „Wenn Bedingung X eintritt, tue Y, sofern Z gilt“. Je mehr solcher Regeln aktiv sind, desto komplexer werden mögliche Wechselwirkungen.
Die Studie: Zwei Lager mit gegensätzlichen Schwächen
Ein Forschungsteam des CRESSET Lab der Toronto Metropolitan University hat sich genau dieser Frage gewidmet: Können große Sprachmodelle – also KI-Systeme wie GPT-4o oder Gemini 2.5 Pro – diese Bedrohungen zuverlässig erkennen? Und wie schlagen sie sich im Vergleich zu klassischen statischen Analyse-Tools?
Das Besondere an dieser Studie ist, dass sie nicht nur die KI-Modelle kritisch bewertet, sondern auch das symbolische Gegenstück unter die Lupe nimmt. Für den Vergleich nutzten die Forscher ihr eigens entwickeltes Framework oHIT (openHAB Interaction Threat Identification), das auf symbolischem Reasoning – also strukturierter, regelbasierter Logikauswertung – basiert. Getestet wurden fünf LLMs: Llama 3.1 8B, Llama 70B, GPT-4o, Gemini 2.5 Pro und DeepSeek-R1, jeweils ohne Beispiele (Zero-Shot), mit einem Beispiel (One-Shot) und mit zwei Beispielen (Two-Shot) – ein in der KI-Forschung übliches Verfahren, um zu messen, wie gut ein Modell aus wenigen Hinweisen lernt.
Das Testmaterial war bewusst zweigeteilt: ein Real-World-Datensatz mit 145 manuell verifizierten Regelinteraktionen aus der openHAB-Community sowie ein Mutation-Datensatz mit 2.495 synthetisch erzeugten Regelsätzen, bei denen gezielt Bedrohungen eingebettet wurden, um Mustererkennung zu brechen und echtes strukturelles Reasoning zu testen.
Das Dilemma: Strukturblindheit gegen Alert Fatigue
Die Ergebnisse der im Fachjournal Empirical Software Engineering veröffentlichten Studie offenbaren ein symmetrisches Problem auf beiden Seiten.
Das symbolische Analyse-Tool oHIT liefert nahezu 100% Recall – es findet praktisch jede theoretische Regelüberschneidung. Die Kehrseite: Es ist kontextblind. Es kann nicht beurteilen, ob ein gefundener Konflikt in der Praxis tatsächlich relevant ist. Das Ergebnis sind hohe False-Positive-Raten und Alert Fatigue – ein Zustand, bei dem Sicherheitsverantwortliche so viele Fehlalarme erhalten, dass sie beginnen, echte Warnungen zu ignorieren. Ein konkretes Beispiel aus der Studie: Das Tool meldet einen Konflikt zwischen einer Regel, die um „8:00 Uhr morgens“ ausgelöst wird, und einer, die auf „Sonnenuntergang“ reagiert – obwohl beide sich im Alltag niemals überschneiden. Für einen Menschen ist das offensichtlich; für das statische Tool nicht.
Die LLMs zeigen das umgekehrte Profil. Sie verstehen den Kontext und die menschliche Absicht hinter einer Regel gut – genau das, womit statische Analyse-Tools traditionell kämpfen. Bei Bedrohungen, die sich aus dem Inhalt einzelner Regeln ergeben, liefern sie brauchbare Ergebnisse. Sobald jedoch strukturelle Abhängigkeiten zwischen mehreren Regeln ins Spiel kommen – Kaskaden, Widersprüche, sich gegenseitig bedingende Zustände – bricht die Erkennungsleistung ein.
Besonders aufschlussreich ist dabei ein kontraintuitiver Befund: Llama 70B, das deutlich größere Modell, schnitt in mehreren Experimenten schlechter ab als das kleinere Llama 8B. Die Erklärung der Forscher: Größere Modelle ohne explizites Reasoning-Alignment neigen dazu, auf lokale Sprachmuster überzufitten statt strukturelle Zusammenhänge zu erfassen. Modellgröße allein garantiert also keine bessere Sicherheitsanalyse. Unter dem Druck der 2.495 mutierten Regelsätze zeigten beide Llama-Varianten vollständige Leistungseinbrüche bei strukturabhängigen Bedrohungen. Selbst GPT-4o und Gemini 2.5 Pro, die sich als robuster erwiesen, konnten keine konsistente Zuverlässigkeit gewährleisten.
Die Lösung: Ein neuro-symbolischer Hybrid
Die Forscher reagieren auf dieses Dilemma nicht mit einem Entweder-oder, sondern mit einer klar durchdachten Aufgabenteilung. In ihrer LLM-oHIT Reconciliation Architecture übernimmt das symbolische Tool weiterhin die initiale Suche – mit seinem hohen Recall findet es alle potenziellen Bedrohungen. Das LLM bekommt anschließend nicht die Aufgabe, selbst im Code nach Schwachstellen zu suchen. Stattdessen wird ihm der Stapel der vom statischen Tool generierten Warnungen übergeben, um als semantischer Schiedsrichter zu entscheiden: Ist dieser Alarm ein echter Threat oder eine harmlose, beabsichtigte Interaktion?
Die Ergebnisse dieses Ansatzes sind konkret messbar – und besonders die kategoriespezifischen Zahlen machen den Mehrwert greifbar. Die Gesamtpräzision stieg im besten Hybrid-Setting (oHIT kombiniert mit Gemini 2.5 Pro im Two-Shot-Verfahren) von 73% auf 93%, ein Gewinn von 20 Prozentpunkten, der direkt aus der Reduktion von Fehlalarmen resultiert. Noch deutlicher wird der Effekt bei einzelnen Bedrohungskategorien: Bei Weak Trigger Cascades – Regelketten, die unbeabsichtigt weitere Aktionen auslösen – verbesserte sich die Präzision von 17% auf 83%. Das bedeutet: Ohne den LLM-Filter waren mehr als acht von zehn Warnungen in dieser Kategorie Fehlalarme. Bei Strong Trigger Cascades stieg die Präzision von 46% auf 85%, bei Weak Action Contradictions von 84% auf 93%. Gleichzeitig gelang es dem Hybrid, 100% der sogenannten Strong Condition Cascades zu erkennen, die das statische Tool aufgrund zu starrer Syntaxregeln zuvor übersehen hatte.
Das folgende Schaubild aus dem Studien-Repository zeigt den genauen Ablauf der Pipeline:
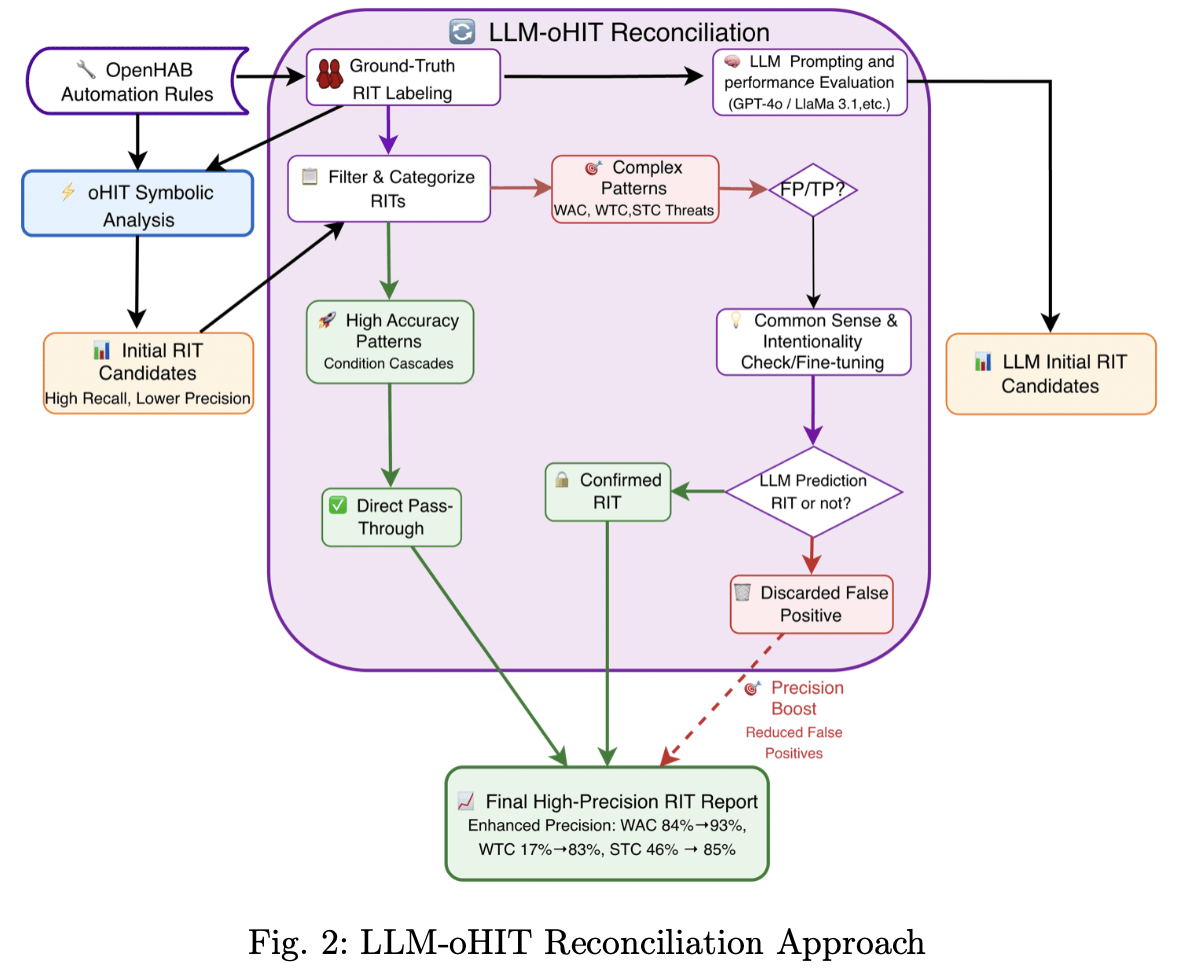
Der LLM-oHIT Reconciliation Approach des CRESSET Lab: Das symbolische Analyse-Tool oHIT liefert zunächst alle Kandidaten mit hohem Recall. Das LLM übernimmt anschließend die Rolle des semantischen Schiedsrichters – es prüft komplexe Muster auf ihre tatsächliche Relevanz und verwirft Fehlalarme. Das Ergebnis ist ein abschließender Bericht mit deutlich gesteigerter Präzision. Abbildung: CRESSET Lab, Toronto Metropolitan University (github.com/cresset-lab/StaticAnalysis_vs_LLM)
Die Autoren beschreiben den Kerngedanken dahinter pointiert: Sicherheit sei nicht mehr nur eine Frage der Code-Korrektheit, sondern auch der semantischen Absicht. Neuronale Netze seien probabilistisch – sie arbeiten mit Wahrscheinlichkeiten; symbolische Logik hingegen liefere die formalen Garantien, die kritische Infrastruktur erfordert. Die Zukunft sicherheitskritischer Systeme liegt nach Einschätzung der Forscher in der Kombination beider Ansätze.
Einordnung für die Praxis
Was bedeutet das für Teams, die heute IoT-Systeme entwickeln, betreiben oder absichern? Zunächst die direkte Konsequenz: Wer LLMs als vollständigen Ersatz für formale Sicherheitsanalyse-Tools in Betracht zieht, sollte das auf Basis dieser Studie verwerfen. Kein einziges der fünf getesteten Modelle – darunter die aktuell leistungsfähigsten verfügbaren Systeme – lieferte konsistente Ergebnisse bei komplexen Regelstrukturen. Und ein größeres Modell zu wählen löst das Problem nicht: Reasoning-Alignment, nicht Parameterzahl, entscheidet über Robustheit.
Das gilt umso mehr in Bereichen, in denen Automatisierungsregeln nicht nur Komfort steuern, sondern physische Sicherheitsmechanismen – Schlösser, Alarmanlagen, Zugangssysteme oder industrielle Steuerungen. Dort sind die Konsequenzen eines übersehenen Interaction Threats erheblich. Hinzu kommt ein praktischer Infrastrukturaspekt, den die Studie am Rande dokumentiert: Gemini 2.5 Pro produzierte während der Experimente über 6.000 HTTP-Fehler durch API-Ratenlimits und Serverausfälle. Wer cloud-basierte KI-Dienste in sicherheitskritische Analysepipelines integriert, muss deren Verfügbarkeit als eigenständiges Risiko einkalkulieren.
Gleichzeitig zeigt die Studie, dass auch der alleinige Einsatz symbolischer Tools seine Grenzen hat. Wer Sicherheitsverantwortliche mit einer Flut von Fehlalarmen überhäuft, erreicht das Gegenteil von mehr Sicherheit. Der hybride Ansatz – statische Analyse für strukturelle Vollständigkeit, LLM für semantische Filterung – ist kein theoretisches Konstrukt mehr, sondern ein empirisch validiertes Verfahren mit messbarem Mehrwert.
Für die IoT-Branche markiert das einen Reifepunkt: nicht mehr die Frage, ob KI in der Sicherheitsanalyse eine Rolle spielen soll, sondern welche Rolle sie präzise übernehmen kann – und welche nicht.
Benutzer-Bewertung
( Stimmen)Auch lesenswert











