

When AI Meets IoT Security: Why LLMs Cannot Replace Static Analysis Tools — Yet

AI models like GPT-4o or Gemini 2.5 Pro are impressively versatile — but can they replace what formal analysis tools have reliably delivered for years in safety-critical IoT environments? A new peer-reviewed study offers a nuanced answer: neither approach is sufficient alone, but together they are.
- Researchers at Toronto Metropolitan University benchmarked GPT-4o, Gemini 2.5 Pro, DeepSeek-R1, and two Llama variants against a symbolic analysis tool for detecting rule interaction threats in openHAB automation systems — across 145 real-world and 2,495 synthetically mutated rulesets.
- LLMs are structurally blind to cross-rule dependencies and hallucinate under adversarial pressure; static analysis tools reliably find all threats but generate so many false positives that they become difficult to use in practice.
- The researchers’ hybrid approach combines both methods and boosts detection precision from 73% to 93% — demonstrating how neural and symbolic AI complement rather than replace each other.
The Security Problem in Connected Home Automation Systems
Anyone running a smart home typically sets up automation rules: if the front door opens after 11 PM, the alarm system should activate. If it is 8:30 AM on a weekday, the kitchen light, coffee maker, and morning radio should switch on. Individually, these rules are harmless — in combination, they can produce unintended and potentially dangerous interactions.
A concrete example from the study: Rule 1 automatically turns on the hallway light at 8:30 AM each weekday morning. Rule 2 unlocks the front door and opens the garage door whenever the hallway light turns on, assuming someone is leaving for work. But if the resident is working from home that day — or is not home at all — the system still unlocks the front door and opens the garage, unattended, for hours. One rule triggers another: this is what the researchers call a Trigger Cascade.
In research, these situations are known as Rule Interaction Threats (RITs) — security threats that emerge from the interplay of multiple automation rules. They fall into three broad categories: Action Contradictions (two rules issue conflicting commands to the same device), Trigger Cascades (one rule unintentionally triggers a chain of further rules), and Condition Cascades (mutually influencing conditions produce unpredictable states).
Platforms like openHAB, one of the most widely used open-source home automation solutions, rely on so-called TAC rules (Trigger–Action–Condition) — the pattern of “if event X occurs, do Y, provided Z holds.” The more rules are active, the more complex the potential interactions become.
The Study: Two Camps With Opposing Weaknesses
A research team at the CRESSET Lab of Toronto Metropolitan University set out to answer exactly this question: can large language models — AI systems like GPT-4o or Gemini 2.5 Pro — reliably detect these threats? And how do they compare to classical static analysis tools?
What makes this study notable is that it subjects both sides to equal scrutiny. For the comparison, the researchers used their own framework oHIT (openHAB Interaction Threat Identification), which is based on symbolic reasoning — structured, rule-based logical evaluation. Five LLMs were tested: Llama 3.1 8B, Llama 70B, GPT-4o, Gemini 2.5 Pro, and DeepSeek-R1, each in three settings: without examples (zero-shot), with one example (one-shot), and with two examples (two-shot) — a standard method in AI research for measuring how well a model learns from minimal guidance.
The test data was deliberately split into two sets: a real-world benchmark of 145 manually verified rule interactions from the openHAB community, and a mutation dataset of 2,495 synthetically generated rulesets in which specific threats were deliberately injected to break pattern matching and evaluate genuine structural reasoning.
The Dilemma: Structural Blindness vs. Alert Fatigue
The results of the study, published in the journal Empirical Software Engineering, reveal a symmetrical problem on both sides.
The symbolic analysis tool oHIT achieves near 100% recall — it finds virtually every theoretical rule overlap. The downside: it is context-blind. It cannot assess whether a detected conflict is actually relevant in practice. The result is a high false-positive rate and alert fatigue — a state in which security teams receive so many false alarms that they begin to ignore genuine warnings. A concrete example from the study: the tool flags a conflict between a rule set to trigger at “8:00 AM” and one that activates at “sunset” — even though the two will never overlap in everyday use. To a human, this is obvious; to the static tool, it is not.
LLMs show the opposite profile. They are good at understanding context and human intent behind a rule — exactly what static analysis tools traditionally struggle with. For threats arising from the content of individual rules, they deliver usable results. But as soon as structural dependencies across multiple rules come into play — cascades, contradictions, mutually dependent states — detection performance breaks down.
Particularly striking is a counterintuitive finding: Llama 70B, the significantly larger model, underperformed the smaller Llama 8B in several experiments. The researchers’ explanation: larger models without explicit reasoning alignment tend to overfit to local language patterns rather than capturing structural relationships. Model size alone does not guarantee better security analysis. Under the pressure of the 2,495 mutated rulesets, both Llama variants collapsed on structure-dependent threats. Even GPT-4o and Gemini 2.5 Pro, which proved more robust, could not guarantee consistent reliability.
The Solution: A Neuro-Symbolic Hybrid
The researchers respond to this dilemma not with an either-or choice, but with a clearly reasoned division of labour. In their LLM-oHIT Reconciliation Architecture, the symbolic tool continues to handle the initial search — using its high recall to surface all potential threats. The LLM is then not asked to search the code for vulnerabilities itself. Instead, it receives the stack of alerts generated by the static tool and acts as a semantic adjudicator: is this alert a genuine threat, or a harmless, intentional interaction?
The results of this approach are concretely measurable — and the category-specific numbers make the benefit tangible. Overall precision increased from 73% to 93% in the best hybrid configuration (oHIT combined with Gemini 2.5 Pro in two-shot mode), a gain of 20 percentage points driven directly by the reduction of false positives. The effect is even more striking at the category level: for Weak Trigger Cascades — rule chains that unintentionally trigger further actions — precision improved from 17% to 83%. In other words, without the LLM filter, more than eight out of ten alerts in this category were false alarms. For Strong Trigger Cascades, precision rose from 46% to 85%; for Weak Action Contradictions, from 84% to 93%. At the same time, the hybrid successfully recovered 100% of the Strong Condition Cascades that the static tool had missed due to overly rigid syntax rules.
The following diagram from the study’s repository illustrates the exact pipeline:
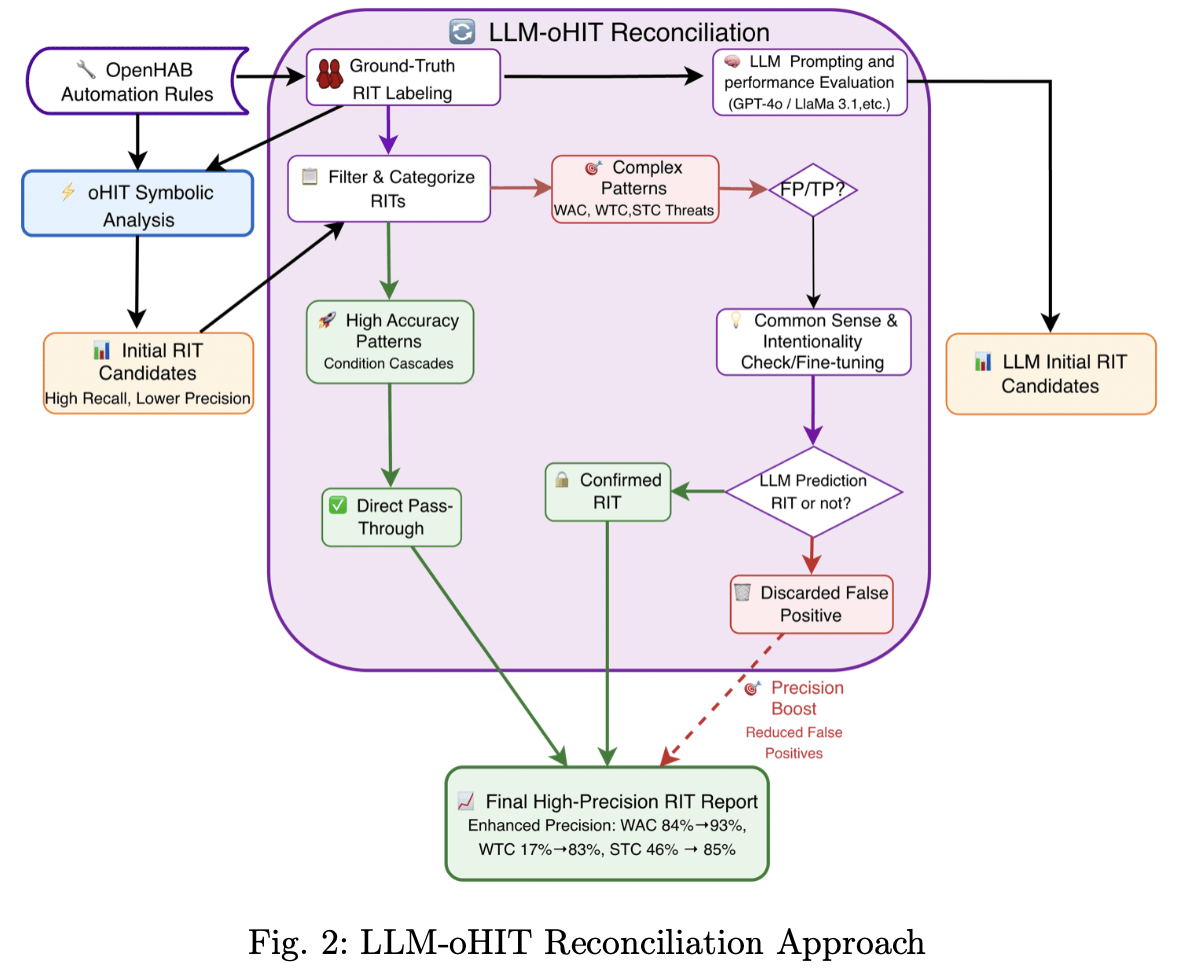
The LLM-oHIT Reconciliation Approach by the CRESSET Lab: the symbolic analysis tool oHIT first surfaces all candidates with high recall. The LLM then acts as a semantic adjudicator — checking complex patterns for real-world relevance and discarding false positives. The result is a final report with significantly enhanced precision. Image: CRESSET Lab, Toronto Metropolitan University (github.com/cresset-lab/StaticAnalysis_vs_LLM)
The authors summarise the underlying insight concisely: security is no longer just a matter of code correctness — it is about semantic intent. Neural networks are probabilistic; symbolic logic provides the formal guarantees required for critical infrastructure. The future of safety-critical systems, in the researchers’ assessment, lies in combining both approaches.
Implications for Practice
What does this mean for teams developing, operating, or securing IoT systems today? The direct conclusion is clear: anyone considering LLMs as a full replacement for formal security analysis tools should reconsider on the basis of this study. Not one of the five tested models — including the most capable systems currently available — delivered consistent results on complex rule structures. And choosing a larger model does not solve the problem: reasoning alignment, not parameter count, determines robustness.
This matters most in contexts where automation rules govern not just convenience, but physical safety mechanisms — locks, alarm systems, access controls, or industrial controllers. There, the consequences of a missed interaction threat are significant. There is also a practical infrastructure dimension the study documents in passing: during the experiments, Gemini 2.5 Pro generated over 6,000 HTTP errors from API rate limits and service outages. Teams integrating cloud-based AI services into safety-critical analysis pipelines need to treat availability as a risk factor in its own right.
At the same time, the study shows that relying on symbolic tools alone has its limits too. Overwhelming security teams with floods of false alarms achieves the opposite of better security. The hybrid approach — static analysis for structural completeness, LLM for semantic filtering — is no longer a theoretical construct, but an empirically validated method with measurable results.
For the IoT industry, this marks a maturity milestone: the question is no longer whether AI should play a role in security analysis, but which role it can reliably fill — and which it cannot.
User Review
( votes)You may also like










