

SGP.32 im IoT: Warum es im Labor funktioniert, aber an den Schnittstellen scheitert
Im Umfeld des aktuellen Mobile World Congress und der Embedded World, wird SGP.32 erneut als der nächste große Sprung für eSIM im IoT gehandelt. Die Richtung stimmt. Riskant ist nur, dass wir Adoption weiter als technischen Meilenstein erzählen, während die eigentlichen Bremsklötze erst später sichtbar werden: im Produktivbetrieb, an den Schnittstellen zwischen den beteiligten Parteien.
- SGP.32 scheitert meist nicht am Profil-Download oder an der Aktivierung, sondern im Produktivbetrieb an den Schnittstellen zwischen Gerät, eUICC, RSP, Netz und Enterprise-IT.
- Ein typisches Muster: „Alles ist grün“, aber Enterprise-Traffic erreicht die Anwendung nicht – wegen fehlender Abstimmung bei APN, IP-Pools, Firewall-Regeln, privatem Routing/VPNs und Policies.
- Für Skalierung braucht es Operability: klare Incident-Verantwortung (RACI), gemeinsame Evidenz und Audit-Logs über alle Parteien hinweg, Ende-zu-Ende-SLOs sowie ein workflowbasiertes „Single Pane of Glass“ statt nur Dashboards.
SGP.32 scheitert selten, weil der Standard unvollständig wäre. Es scheitert, weil eine Multi-Party-Umsetzung ohne gemeinsames Betriebsmodell „Entkopplung“ in diffuses Ownership verwandelt. Im Labor spielt jede Komponente sauber mit. In der Produktion entscheiden die Übergaben darüber, ob Kunden Vertrauen fassen.
Was ist SGP.32 – und warum es wichtig ist
eSIM, genauer eUICC, ist im IoT wichtig, weil Geräte über Jahre hinweg im Feld stehen und oft schwer erreichbar sind. Physische SIM-Wechsel sind langsam, teuer und im Flottenmaßstab operativ unrealistisch.
SGP.32 ist der GSMA-Standard, der das Remote Provisioning für IoT modernisieren soll. Er ermöglicht den Remote-Download und die Aktivierung von Profilen im großen Maßstab. Das ist wichtig – aber es ist auch der Teil, den man am leichtesten zeigen kann. Adoption scheitert selten am Download.
Der harte Teil beginnt nach dem Download
Im realen Betrieb entscheidet sich, ob ein Enterprise-Kunde das System betreiben kann, ohne am Ende selbst zur Integrationsfirma zu werden. Sobald SGP.32 in Produktion ist, hängt „Konnektivität funktioniert“ von der gesamten Kette ab: Gerät und Firmware, eUICC-Verhalten, die Provisioning-Plattform, das Mobilfunknetz – und ebenso von Enterprise-Voraussetzungen wie APNs, IP-Pools, Firewall-Regeln, privatem Routing, VPN-Konnektivität und Policy-Einschränkungen. SGP.32 ist ein kritischer Baustein, aber eben nur ein Baustein.
Im realen Betrieb entscheidet sich, ob ein Enterprise-Kunde das System betreiben kann, ohne am Ende selbst zur Integrationsfirma zu werden.
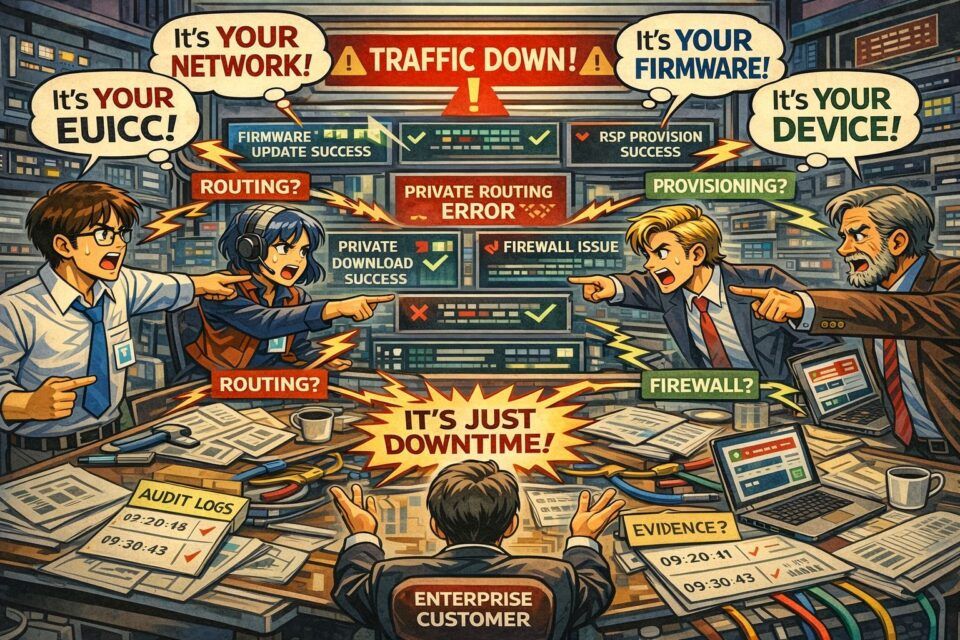
„Alles ist grün“, aber die Anwendung sieht nichts
Ein Muster, das sich in vielen Deployments wiederholt, ist schlicht: Das Profil wird heruntergeladen und aktiviert, jede Komponente meldet Erfolg – aber Enterprise-Traffic kommt nie bei der Anwendung an.
In vielen Fällen ist das Provisioning nicht kaputt. Kaputt ist die Abstimmung. Der APN zeigt in die falsche Umgebung, der IP-Pool passt nicht zum erwarteten Adressraum, Firewall-Regeln blockieren Traffic, private Routen fehlen oder sind inkonsistent. Jede Schicht kann für sich genommen korrekt sein – und genau deshalb kann das Kundenerlebnis Ende-zu-Ende trotzdem falsch sein.
Fragmentierung macht aus Incidents parallele Untersuchungen
Verschiedene Teams beschreiben denselben Incident in unterschiedlicher Sprache. Connectivity-Teams nennen es Routing. Device-Teams nennen es Firmware. RSP-Teams nennen es Provisioning. Der Kunde nennt es einen Ausfall.
Das ist keine Semantik. So sieht Fragmentierung unter Druck aus. Wenn Verantwortlichkeiten entlang von Komponenten organisiert sind, werden Incidents zu parallelen Untersuchungen – mit selektivem Evidenz-Sharing und langsamem Austausch von Audit-Logs, „nur zur Sicherheit“. Ein großer Teil der Energie fließt dann in Schuldabwehr statt in die schnelle Wiederherstellung des Services.
Reparaturzeiten steigen. Vertrauen sinkt. Und am Ende heißt es: „SGP.32 ist nicht bereit“ – obwohl das Kernproblem oft nicht der Standard ist, sondern das Betriebsmodell rundherum.
Der Shift, den SGP.32 braucht: Von Features zu Operability
Wenn SGP.32 über Early Adopters hinaus skalieren soll, muss sich die Diskussion von Feature-Listen hin zu Operability verschieben.
Das bedeutet:
- Klare Incident-Ownership, einschließlich der Frage, wer Enterprise-Routing-Alignment verantwortet und wer die Ende-zu-Ende-Triage führt
- Eine gemeinsame Faktenbasis, ein gemeinsamer Evidenzsatz, konsistente Zeitstempel, konsistente Zustände, nachvollziehbare Audit-Logs über Device, eUICC, RSP und Netzwerk hinweg
- Erfolgsmetriken, die Flottenergebnisse messen, nicht Komponenten-Erfolg – also dass Traffic nach der Aktivierung zuverlässig die Anwendung erreicht
- Ein „Single Pane of Glass“, das Workflow plus Datenmodell ist – nicht ein Dashboard: konsistente Terminologie, konsistente Zustände, klare Übergaben und Incident-Choreografie über Parteien hinweg
Hier verschiebt sich das Ökosystem von „Komponenten, die konform sind“ zu „Systemen, die sich zuverlässig betreiben lassen“.
Mehr Optionen erhöhen den Druck an den Schnittstellen
Das wird umso wichtiger, je mehr zusätzliche Optionen ins System kommen. Private-5G-Ansätze sowie satellitengestützte Multi-Orbit- und Multi-Constellation-(NTN)-Konnektivität erhöhen Reichweite und Resilienz. Gleichzeitig steigt die Zahl der Policies, Bearer und Failure Modes.
Optionalität ist wertvoll, solange der Betrieb einfach bleibt. Wenn nicht, multipliziert sich Komplexität genau dort, wo es heute schon bricht: an den Schnittstellen zwischen den beteiligten Parteien.
Wer SGP.32 im großen Maßstab betreibt, weiß längst: Der harte Teil ist nicht der Download. Der harte Teil ist alles, was darum herum funktionieren muss
Der beste Zeitpunkt, das zu lösen, ist vor der Eskalation
Viele Teams organisieren sich gerade rund um IoT-Konnektivität und eSIM neu. Das ist der richtige Moment, Accountability in Architektur und Betrieb einzubauen – nicht erst nach der ersten Eskalation.
Wer SGP.32 im großen Maßstab betreibt, weiß längst: Der harte Teil ist nicht der Download. Der harte Teil ist alles, was darum herum und danach funktionieren muss, damit „grün“ tatsächlich „läuft“ bedeutet.
(Aus dem Englischen übersetzt)
Auch lesenswert













