KI-gestützte Predictive Maintenance im IIoT: Es ist kompliziert

Predictive Maintenance gilt als Schlüsselanwendung für Künstliche Intelligenz im industriellen Internet der Dinge (Industrial Internet of Things, IIoT). Sensoren erfassen Schwingungen, Temperaturen, Ströme oder Druckwerte, KI-Modelle sollen daraus erkennen, wann Maschinen aus dem Normalbetrieb in einen kritischen Zustand übergehen. Ziel ist es, Ausfälle frühzeitig zu erkennen und Wartung planbar zu machen. In der Praxis scheitern viele dieser Projekte jedoch nicht an fehlender Rechenleistung oder Sensorik, sondern an einem grundlegenden Datenproblem.
Warum Predictive-Maintenance-KI so schwer zu trainieren ist
Industrielle Anlagen sind darauf ausgelegt, zuverlässig zu funktionieren. Ausfälle sind selten – und genau das ist aus Sicht des maschinellen Lernens problematisch. Während enorme Mengen an Daten aus dem Normalbetrieb vorliegen, existieren nur sehr wenige gelabelte Beispiele für echte Fehler oder Ausfälle. Die Datensätze sind stark unausgeglichen: „Normalzustand“ dominiert, „Fehlerzustand“ ist die Ausnahme.
Für KI-Modelle bedeutet das ein hohes Risiko von Fehlanpassungen. Ein Modell kann hohe Genauigkeitswerte erzielen, indem es fast immer „kein Fehler“ vorhersagt, ohne tatsächlich in der Lage zu sein, kritische Zustände zuverlässig zu erkennen. Dieses Problem der Klassenungleichgewichtung ist eines der zentralen Hindernisse für den produktiven Einsatz von KI in der vorausschauenden Wartung.
Statistische Datenaufbereitung mit SMOTE
Ein verbreiteter Ansatz zur Entschärfung des Problems ist die künstliche Vergrößerung der seltenen Fehlerklasse. Die bekannteste Methode ist SMOTE (Synthetic Minority Oversampling Technique). Dabei werden neue Fehlerdaten erzeugt, indem zwischen vorhandenen Fehlerbeispielen interpoliert wird. Der Datensatz wird ausgeglichener, klassische Machine-Learning-Modelle lassen sich stabiler trainieren.
Der Vorteil von SMOTE liegt in seiner Einfachheit und geringen Rechenkosten. Der Nachteil ist, dass die erzeugten Daten oft nur mathematisch, nicht aber physikalisch realistisch sind. Komplexe zeitliche oder nichtlineare Fehlerverläufe lassen sich so nur eingeschränkt abbilden.
Generative Modelle und GANs
Ein weiterentwickelter Ansatz nutzt generative KI-Modelle, insbesondere Generative Adversarial Networks (GANs). Diese Modelle lernen die statistische Struktur realer Fehlerdaten und erzeugen neue synthetische Beispiele, die den Originaldaten sehr ähnlich sind. Dadurch lassen sich realistischere Fehlerszenarien erzeugen, insbesondere bei komplexen Sensordaten und Zeitreihen.
GANs können das Trainingsproblem deutlich besser adressieren als rein statistische Methoden. Gleichzeitig sind sie aufwendig zu trainieren, schwer zu validieren und anfällig für methodische Fehler, etwa wenn synthetische Daten unbemerkt in Testdaten gelangen. Zudem ist die Nachvollziehbarkeit für industrielle Anwender begrenzt.
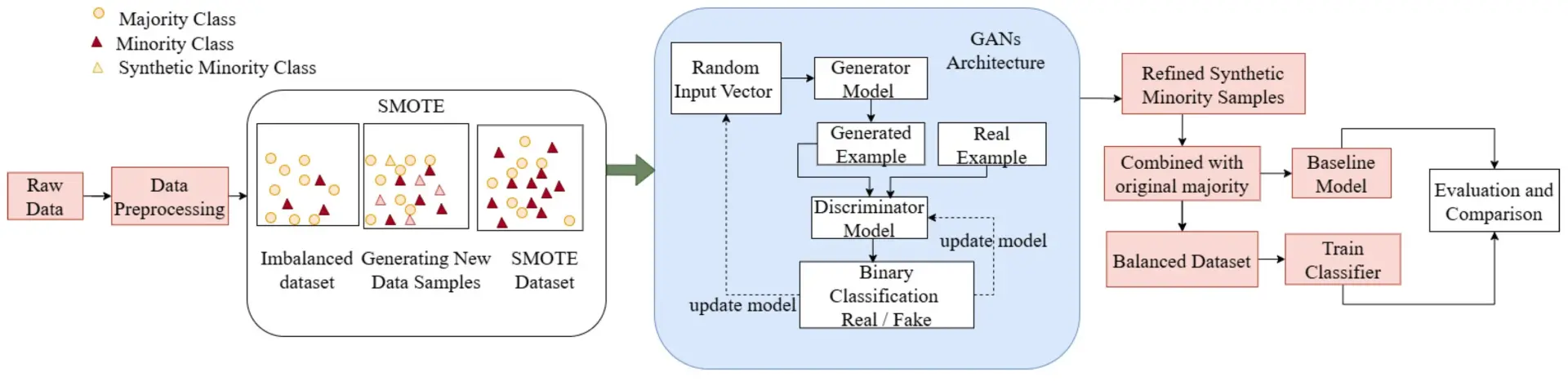
Proposed workflow model using data generating techniques. Zafat et al, 2025
Kombinationen aus SMOTE und GANs
Ein hybrider Ansatz kombiniert beide Methoden. Genau hier setzt das Paper „GenIIoT: Generative Models Aided Proactive Fault Management in Industrial Internet of Things“ von Isra Zafat, Arshad Iqbal, Maqbool Khan, Naveed Ahmad und Mohammed Ali Alshara, veröffentlicht 2025 im Journal Information (MDPI), an.
Die Idee: SMOTE sorgt zunächst für eine bessere Klassenbalance, während GANs anschließend realistischere Fehlermuster erzeugen. Der Mischansatz soll die Schwächen beider Methoden abmildern. Die Autoren zeigen anhand mehrerer industrieller Datensätze, dass sich damit die Erkennungsleistung verschiedener KI-Modelle deutlich verbessern lässt – insbesondere bei stark unausgeglichenen Daten.
Alternative Strategien jenseits künstlicher Fehlerdaten
Nicht alle Ansätze setzen auf synthetische Daten. Eine alternative Strategie ist Anomalieerkennung: Das Modell lernt ausschließlich den Normalbetrieb und meldet Abweichungen. Das reduziert den Bedarf an Fehlerlabels, erhöht aber das Risiko von Fehlalarmen.
Weitere Ansätze nutzen Transfer Learning, bei dem Modelle auf ähnlichen Maschinen oder Simulationen vortrainiert werden, oder hybride Systeme, die KI mit regelbasierten Verfahren und physikalischen Modellen kombinieren. Diese Methoden sind oft robuster, aber komplexer in der Implementierung.
Viele Ansätze für ein Grundproblem
Alle beschriebenen Lösungswege reagieren auf dasselbe Grundproblem: Der industrielle Alltag liefert zu wenige Fehlerdaten, um KI klassisch zu trainieren. SMOTE, GANs, Mischansätze und alternative Lernstrategien sind Versuche, diese strukturelle Lücke zu schließen. Keine Methode ist universell überlegen. Entscheidend sind Anlagenkontext, Datenqualität, Sicherheitsanforderungen und die Frage, wie gut ein System erklärbar und wartbar sein muss.
Zusammenfassung (tl;dr)
- Predictive Maintenance scheitert oft an zu wenigen echten Fehlerdaten
- SMOTE ist einfach, erzeugt aber begrenzt realistische Daten
- GANs liefern realistischere Fehler, sind aber komplex und schwer zu validieren
- Mischansätze wie im Paper von Zafat et al. kombinieren beide Methoden
- Alternative Strategien umgehen Fehlerdaten, bringen aber neue Risiken mit sich
Weiterführende Links
- GenIIoT: Generative Models Aided Proactive Fault Management in IIoT (Zafat et al., 2025)
Hybridansatz aus SMOTE und GANs zur Verbesserung des Trainings für Fault Management/Predictive Maintenance im IIoT. - Review of imbalanced fault diagnosis technology based on generative adversarial networks (Oxford Academic, 2024)
Open-Access-Review zu Klassenungleichgewicht in der Fehlerdiagnose und zur Rolle von GANs als Daten-Enhancement-Ansatz. - Generate Synthetic Pump Signals Using Conditional GAN (MathWorks/MATLAB)
Praxisnahe Beispielanleitung zur Erzeugung synthetischer Pumpensignale für PdM mit Conditional GANs. - TimeGAN: Time-series Generative Adversarial Networks (NeurIPS 2019 – PDF)
Klassisches Paper zu TimeGAN als generativem Modell für realistische synthetische Zeitreihen (relevant für PdM-Sensordaten). - Evaluating Lightweight GAN- and Adapted CTGAN-Based Data Synthesis for Predictive Maintenance (PDF, 2025)
Konferenzpaper-PDF zur Synthese von Sensordaten für Predictive Maintenance und zum Vergleich GAN/CTGAN-naher Ansätze. - Fair Synthetic Time Series Data for Predictive Maintenance (DiVA – PDF, 2024)
Thesis-PDF zur Generierung synthetischer PdM-Zeitreihen und zur Bewertung von Qualität/Verzerrungen. - Try Anomaly Detection for Predictive Maintenance (KNIME – Blog)
Praxisorientierter Einstieg in Anomalieerkennung als PdM-Strategie.
Benutzer-Bewertung
( Stimmen)Auch lesenswert