In the Internet of Things, large amounts of data need to be transferred and processed quickly. However, the cloud with its relatively narrow bandwidth is overwhelmed with it – edge computing as data processing on-site is getting increasingly important. Is the end of the cloud getting closer?
The Internet of Things (IoT) is still on the rise – and can hardly be stopped. According to various studies, we will live in a world with 20, 50 or 200 billion networked IoT devices in the upcoming years. According to Cisco, the number of IoT sensors will increase to 50 billion by 2020, and by 2030, Intel estimates, 200 billion objects will be connected to the Internet.
Most devices and machines will record their environment via sensors, exchange and analyze data, and act more or less independently. Experts are currently discussing how and where this data should be processed. For data exchange analysis, the Cloud seems to be the first choice. But, in general, this won’t work because IoT devices generate huge amounts of data for which cloud providers cannot provide the necessary bandwidths. For the relatively narrow cloud bandwidth, the amount of data is far too large – and even high-speed networks cannot change this.
Yet, even if the data were transmitted, the data round trip would take much too long. If, for example, an autonomous vehicle encounters an obstacle, there is not enough time to send all data to a cloud server and wait for the command for an evasive maneuver. If a person runs in front of a car, the braking process must be initiated immediately – this is about fractions of seconds.
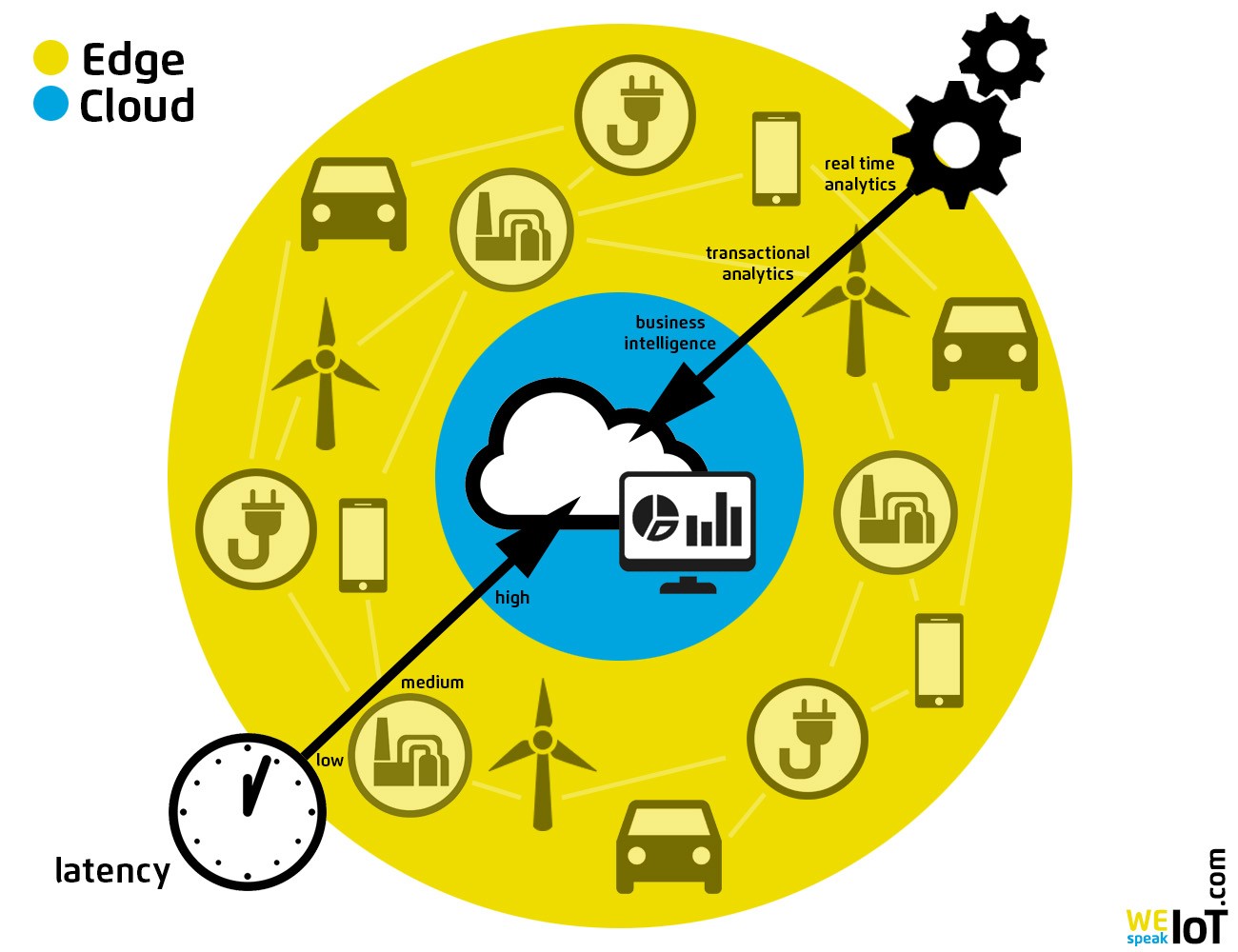
Edge Computing takes on time-critical data processing on-site. The Cloud requires more complex, non-time-critical tasks. Original source: International Journal of Information Technology (IJIT)
Edge data processing on-site
Rapid reaction is only possible if the data is processed directly on-site. Whereas sending the data from the device to the cloud, processing it in a central data center and then returning the result to the device, would prolong the braking process far too much. “We waste time and bandwidth by uploading all the data from IoT devices to the cloud and then back to the net,” says Guido Jouret, CEO of Cisco’s Internet-of-Things division.
It therefore makes good sense to carry out central processing tasks directly at the place where they are being created. This transfer of computing power, applications, data, and services directly to the logical edge of a network is the idea behind edge computing – other common terms are “fog computing”, “local cloud” or “cloudlets”.
With Edge Computing, IT systems are directly installed in or near the products and machines – for example, in the factory hall or on an oil-conveying platform. This way, a large part of the IT and analytics is shifted in or close to the things of the Internet of Things. Edge computing thus avoids the cloud as a possible bottleneck. If low latencies are expected or if data must be available in real time, this approach is the best choice.
End of the Cloud?
But what does Edge mean for the Cloud? Does the Cloud still play a role in a world of 20 billion, 50 billion or 200 billion IoT devices? Or will Edge computing devour the cloud, as Gartner analyst Tom Bittman stated? Will the cloud disappear completely in the not too distant future, as Peter Levine from the venture capital firm Andreessen Horowitz expected?
Clearly, Edge and Cloud Computing are quite different things. That one replaces the other is not very likely. Thus, cloud computing will not become obsolete because there are many useful applications beyond IoT for cloud services. The classic cloud applications – SaaS, IaaS and PaaS – are not affected by the topic at all. And they will live on.
In other words, the cloud will continue to be relevant in the IoT environment. While we cannot use the cloud for situations where large amounts of data are being transferred or where we need a very fast response, the cloud can take at least two roles in an IoT world.
Cloud role in IoT
Firstly, the cloud can be used for IoT applications that are not time-critical or are not directly required by the device. Likewise, complex calculations and analysis cannot be carried out on-site and must be carried out – possibly distributed – on a cloud-based basis. For example, companies could aggregate data from edge devices in the cloud and drive complex analysis there. An autonomous vehicle, for example, collects a multitude of information during the journey, which can be used for comprehensive data analysis, for example, for the improvement of the vehicle software, for the testing or the control. All this is possible as soon as the processes are not time-critical.
Secondly, the cloud can be used to record certain IoT events and data in the long term. On-site information can usually only be stored for a short time and will then be overwritten automatically. To retain all information on-site, would blow the storage capacities of the devices. But in production, for example, it is necessary to ascertain what went wrong. Therefore, all data must be centrally stored and available.
In conclusion, for every concept has its strengths and weaknesses. So, it is about integrating the strengths – and not the weaknesses – of both concepts. Edge’s advantage is the fast processing and short-term storage of small amounts of data, the cloud has its pints in longer-term storage of data or data analysis, that are not time-critical. In the end, it is a matter of finding the right balance between centralized and distributed resources.
You might also want to read: