SGP.32 gewinnt im IoT-Connectivity-Markt an Bekanntheit. Die größere Herausforderung: Produktteams, Solution Architects und Kunden müssen den Standard greifbar erfassen können – vor Beschaffung, Rollout und dem ersten Produktionsvorfall.
Das Wichtigste in Kürze
- Bekanntheit ist nicht Einsatzbereitschaft: Viele Produktteams kennen den Namen SGP.32, doch sie verstehen nicht, was der Standard in Verhalten, Verantwortung und Betrieb konkret verändert.
- Der nächste SGP.32-Durchbruch braucht kein weiteres Feature und kein neues Portal – er braucht einen Playground, der das Verhalten des Standards vor Beschaffung und Rollout sichtbar macht.
- Je kritischer der Anwendungsfall – vernetzte Fahrzeuge, Gesundheitswesen, Industrial IoT – desto gefährlicher wird es, Flexibilität als abstraktes Versprechen zu verkaufen, ohne dass Teams verstehen, was sie kaufen und was sie selbst kontrollieren müssen.
Man kann „SGP.32″ so oft wiederholen, bis der Markt den Namen kennt. Das bedeutet aber nicht, dass der Markt versteht, was damit anzufangen ist.
Diese Adoptionslücke unterschätzt die IoT-Branche immer wieder: Bekanntheit ist nützlich, aber sie ersetzt keine Einsatzbereitschaft. Ein Produktteam hat vielleicht von SGP.32 gehört – dem GSMA-Standard für die Remote-Bereitstellung und das Lebenszyklusmanagement von eSIMs in IoT-Geräten. Ein Solution Architect weiß vielleicht, dass es etwas mit eSIM-Lebenszyklusmanagement zu tun hat. Ein Einkaufsteam hat den Begriff vielleicht schon in Vendor-Präsentationen gesehen.
Verstehen heißt das nicht. Und wer eine Technologie nicht versteht, kauft, steuert und betreibt sie nicht mit Zuversicht.
Enterprise-Vertrieb ist normal. Enterprise-Mystery nicht.
SGP.32 muss kein Spielzeug werden. Es ist ein Enterprise-Standard für ein komplexes Ökosystem, und das sollte niemand kleinreden. Ein Vertriebsprozess, eine geführte Demo oder ein Solution-Workshop sind normal. Die meisten Unternehmen sollten großskalige IoT-Connectivity nicht einfach aktivieren wie ein Testabo.
Aber Enterprise-Vertrieb sollte nicht Enterprise-Mystery bedeuten.
Vor der Beschaffung, vor dem Rollout und vor dem ersten Produktionsvorfall brauchen Produktteams einen klaren Weg, um zu verstehen, was SGP.32 tatsächlich verändert – nicht nur auf der Ebene der Standard-Sprache, sondern auf der Ebene von Verhalten, Verantwortung und operativen Trade-offs. Genau dort sehe ich weiterhin eine Lücke in der aktuellen Diskussion.
Warum Bekanntheit nicht Einsatzbereitschaft bedeutet
Beim erneuten Lesen von Afzal Mangals „IoT: The Hype No One Knows About“ fiel mir wieder ein Muster auf, das große Teile der IoT-Branche durchzieht. Wir verwechseln häufig Aufmerksamkeit mit Adoption. Menschen hören von einer Technologie. Sie stimmen vielleicht sogar zu, dass sie wichtig ist. Aber solange sie die Technologie nicht anfassen, testen, kaputt machen und auf den eigenen Kontext anwenden können, bleibt sie abstrakt. SGP.32 läuft Gefahr, in dasselbe Muster zu fallen.
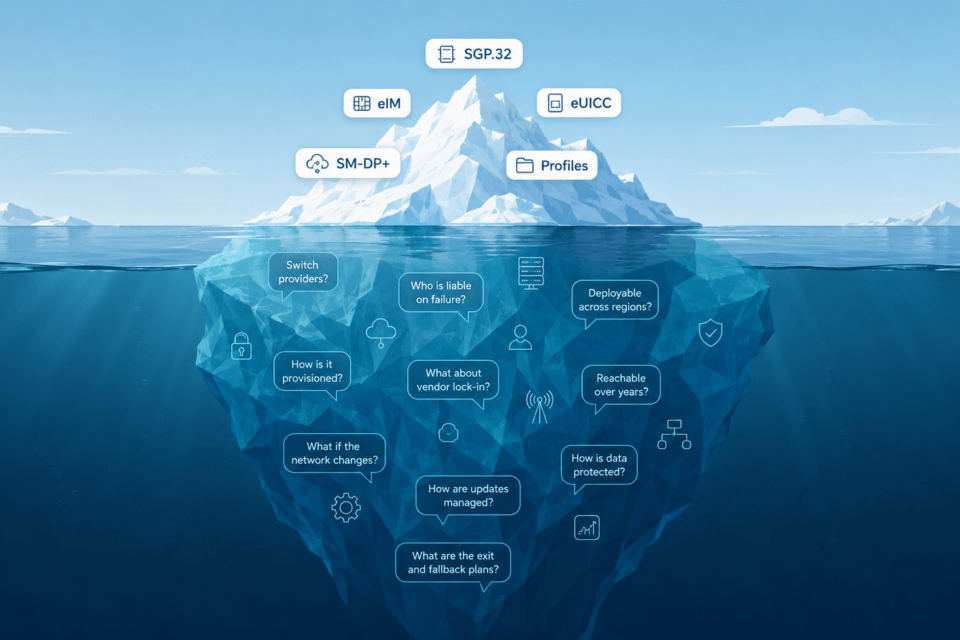
Noch spricht ein Großteil der SGP.32-Diskussion Telekom-Sprache: eIM (der IoT Remote Manager, der zwischen Gerät und Netzwerkinfrastruktur sitzt), eUICC (der eingebettete SIM-Chip), IPAe/d (der IoT Profile Assistant auf der Geräteseite), Profile, Policies, SM-DP+ (die Serverinfrastruktur, die Profile vorbereitet und ausliefert). Alles korrekt. Aber weit entfernt davon, wie viele Produktteams und Solution Architects tatsächlich lernen.
Das Problem ist nicht, dass diese Terminologie existiert. Sie muss existieren. Standards brauchen Präzision. Architekturen brauchen definierte Komponenten. Schnittstellen brauchen Namen. Das Problem beginnt, wenn die Sprache des Standards der einzige Weg wird, den Wert zu verstehen.
Ein Kunde wacht nicht morgens auf und möchte ein eIM. Ein Produktteam beginnt nicht bei IPAe/d. Ein Flottenbetreiber interessiert sich nicht für Profil-Lebenszyklusmanagement als abstraktes Konzept. Sie interessieren sich für Fragen wie:
- Kann ich eine Gerätevariante über mehrere Regionen hinweg ausrollen?
- Kann ich später den Connectivity-Anbieter wechseln, ohne das Gerät anzufassen?
- Kann ich reagieren, wenn die erste Connectivity-Wahl nicht wie erwartet funktioniert?
- Kann ich meine Geräte über lange Lebenszyklen hinweg erreichbar halten?
- Kann ich nachvollziehen, wer wofür verantwortlich ist, wenn etwas ausfällt?
- Kann ich Flexibilität nutzen, ohne operatives Chaos zu erzeugen?
Das ist die Übersetzungsebene, die SGP.32 noch braucht.
Der nächste Durchbruch kommt nicht durch ein weiteres Portal
Der nächste SGP.32-Durchbruch kommt nicht durch eine weitere Feature-Liste. Er kommt nicht durch einen weiteren Portal-Screenshot. Er kommt nicht durch eine weitere Folie mit „Remote Profile Management“, „Carrier-Flexibilität“ oder „zukunftssichere IoT-Connectivity“. Das alles ist wichtig, aber es reicht nicht.
Der nächste Durchbruch kommt, wenn jemand SGP.32 leichter ausprobierbar, erklärbar und nachvollziehbar macht. Mit anderen Worten: SGP.32 braucht einen Playground. Keine Zertifizierungsumgebung. Keine produktionsreife Simulation. Keine vendor-kontrollierte Demo, in der alles funktioniert, weil der Weg bereits vorbereitet ist. Einen Playground. Einen Ort, an dem das Verhalten sichtbar wird – vor Beschaffung, Rollout oder der ersten Eskalation.
Warum Software Defined Vehicles ein interessanter Vergleich sind
Software Defined Vehicles – Fahrzeuge, deren Funktionen Software statt fest verbaute Hardware steuert und die dadurch Over-the-Air-Updates und Ferndiagnosen ermöglichen – sind ein interessanter Vergleich. Nicht weil jedes SDV-Detail eins zu eins auf eSIM übertragbar wäre, sondern weil das Lernmuster dahinter so wirksam ist.
Schon ein kleiner SDV-Playground mit ECUs (Electronic Control Units, den eingebetteten Steuergeräten für Fahrzeugfunktionen), CAN-Bus, einer TCU und Cloud-Anbindung macht die Architektur greifbar. Niemand verwechselt das mit einem Serienfahrzeug. Aber plötzlich ist Vehicle-to-Cloud keine Folie mehr. Man sieht Zustände. Man kann Timing brechen. Man kann Vertrauen testen. Man versteht, warum Connectivity, Backend-Erreichbarkeit und Lebenszyklussteuerung wichtig sind.
Diese Art von praktischer Umgebung leistet etwas, das eine Präsentation selten schafft: Sie macht abstrakte Architektur nachvollziehbar. Das ist relevant, weil moderne vernetzte Produkte nicht um eine isolierte Komponente herum gebaut sind. Sie sind Systeme von Systemen. Der Wert entsteht im Zusammenspiel von Gerät, Connectivity, Cloud, Policy, Lebenszyklus und Betrieb. Das gilt für SDV. Das gilt auch für SGP.32.
Was ein SGP.32-Playground zeigen könnte
Wenn SGP.32 in Compliance-Dokumenten, Telekom-Terminologie und vendor-kontrollierten Demos gefangen bleibt, bleibt der Standard für Spezialisten nachvollziehbar und für alle anderen abstrakt. Das mag in der frühen Phase eines Standards in Ordnung sein. Für eine breitere Adoption reicht es nicht.
Ein nützlicher SGP.32-Playground könnte zeigen:
- Virtuelles Geräte- und eUICC-Verhalten
- Beispielhafte eIM-Abläufe
- Simulierte SM-DP+-Antworten
- Testprofile
- APN- und Routing-Szenarien
- Audit-Trails und Fehlerzustände
- Einfache Policy-Rezepte
Es geht nicht darum, Kunden zu Telekom-Experten zu machen. Genau das Gegenteil. Es geht darum, Produktteams, Solution Architects und Unternehmensverantwortlichen zu zeigen, was sie kaufen, was sie auslagern und was sie weiterhin selbst kontrollieren müssen.
Diese Unterscheidung ist wichtig. Denn viele diskutieren SGP.32 so, als schaffe es nur Freiheit – die Freiheit, Profile zu wechseln, die Freiheit, Connectivity-Anbieter zu wählen, die Freiheit, Geräte über lange Lebenszyklen hinweg zu verwalten. Aber Freiheit ohne Verständnis ist noch keine Kontrolle. Sie ist nur Optionalität. Und Optionalität wird erst dann wertvoll, wenn Kunden verstehen, wie sie sie sicher nutzen.
Warum kritische Anwendungsfälle das noch dringlicher machen
Das wird besonders relevant bei hochkritischen Einsatzszenarien. Bei vernetzten Fahrzeugen ist Connectivity längst nicht mehr nur „die SIM-Karte“. Sie betrifft OTA-Updates, Diagnose, Notfalldienste, Abonnements, regionale Anforderungen, Cybersicherheit und Servicekontinuität. Dieselbe Logik gilt für Gesundheitswesen, Versorgungsunternehmen, Logistik und Industrial IoT.
Je kritischer der Anwendungsfall, desto gefährlicher ist es, Flexibilität als abstraktes Versprechen zu verkaufen. In einem unkritischen Szenario kann unklares Lebenszyklusverhalten Unannehmlichkeiten verursachen. In einem kritischen Szenario kann es operatives Risiko bedeuten.
Deshalb muss SGP.32 nicht nur für Standard-Experten verständlich sein. Auch die Teams brauchen Zugang, die für Produktentscheidungen, Kundenversprechen und Day-2-Operations verantwortlich sind – den laufenden Betrieb nach der Erstinstallation.
Ein Produktteam sollte verstehen, was passiert, wenn ein Profil heruntergeladen, aktiviert, geändert oder entfernt wird. Ein Solution Architect sollte nachvollziehen können, wie das mit Routing, Policies, Connectivity-Erreichbarkeit und Backend-Verhalten zusammenspielt. Ein Customer-Success-Team sollte den Lebenszyklus erklären können, ohne in jedem Gespräch einen Standard-Experten hinzuziehen zu müssen. Wenn das nicht möglich ist, liegt das Problem nicht beim Standard. Es liegt an der fehlenden Übersetzungsebene drumherum.
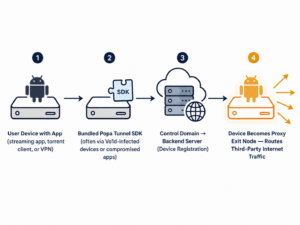
Das knüpft an eine breitere Herausforderung an. Ich habe sie in einem früheren Beitrag auf WeSpeakIoT beschrieben: SGP.32 funktioniert im Labor, scheitert aber an den Grenzen – den Übergaben zwischen Gerät, eUICC, RSP-Infrastruktur, Netzwerk und Unternehmens-IT. Teams, die nie eine Möglichkeit hatten, diese Grenzen in einer sicheren Umgebung zu erleben, kommen unterversorgt in der Produktion an. Ein Playground würde nicht jedes Grenzproblem lösen. Aber er würde die Zahl der Teams verringern, die diesen Grenzen zum ersten Mal in einem laufenden Deployment begegnen.
(Dieser Text ist eine Übersetzung aus dem englischen Original)